Semantic Segmentation Fine Tuning Inference
Fine-Tuning a Semantic Segmentation Model on a Custom Dataset and Usage via the Inference API
Authored by: Sergio Paniego
In this notebook, we will walk through the process of fine-tuning a semantic segmentation model on a custom dataset. The model we'll be using is the pretrained Segformer, a powerful and flexible transformer-based architecture for segmentation tasks.
For our dataset, we'll use segments/sidewalk-semantic, which contains labeled images of sidewalks, making it ideal for applications in urban environments.
Example use-case: This model could be deployed in a delivery robot that autonomously navigates sidewalks to deliver pizza right to your door 🍕
Once we've fine-tuned the model, we'll demonstrate how to deploy it using the Serverless Inference API, making it accessible via a simple API endpoint.
1. Install Dependencies
To begin, we’ll install the essential libraries required for fine-tuning our semantic segmentation model.
2. Loading the Dataset 📁
We'll be using the sidewalk-semantic dataset, which consists of images of sidewalks collected in Belgium during the summer of 2021.
The dataset includes:
- 1,000 images along with their corresponding semantic segmentation masks 🖼
- 34 distinct categories 📦
Since this dataset is gated, you'll need to log in and accept the license to gain access. We also require authentication to upload the fine-tuned model to the Hub after training.
Review the internal structure to get familiar with it!
DatasetDict({
, train: Dataset({
, features: ['pixel_values', 'label'],
, num_rows: 1000
, })
,}) Since the dataset only includes a training split, we will manually divide it into training and test sets. We'll allocate 80% of the data for training and reserve the remaining 20% for evaluation and testing. ➗
Let's examine the types of objects present in an example. We can see that pixels_values holds the RGB image, while label contains the ground truth mask. The mask is a single-channel image where each pixel represents the category of the corresponding pixel in the RGB image.
{'pixel_values': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=1920x1080>,
, 'label': <PIL.PngImagePlugin.PngImageFile image mode=L size=1920x1080>} 3. Visualizing Examples! 👀
Now that we’ve loaded the dataset, let’s visualize a few examples along with their masks to understand its structure better.
The dataset includes a JSON file containing the id2label mapping. We’ll open this file to read the category labels associated with each ID.
id2label.json: 0%| | 0.00/852 [00:00<?, ?B/s]
Id2label: {0: 'unlabeled', 1: 'flat-road', 2: 'flat-sidewalk', 3: 'flat-crosswalk', 4: 'flat-cyclinglane', 5: 'flat-parkingdriveway', 6: 'flat-railtrack', 7: 'flat-curb', 8: 'human-person', 9: 'human-rider', 10: 'vehicle-car', 11: 'vehicle-truck', 12: 'vehicle-bus', 13: 'vehicle-tramtrain', 14: 'vehicle-motorcycle', 15: 'vehicle-bicycle', 16: 'vehicle-caravan', 17: 'vehicle-cartrailer', 18: 'construction-building', 19: 'construction-door', 20: 'construction-wall', 21: 'construction-fenceguardrail', 22: 'construction-bridge', 23: 'construction-tunnel', 24: 'construction-stairs', 25: 'object-pole', 26: 'object-trafficsign', 27: 'object-trafficlight', 28: 'nature-vegetation', 29: 'nature-terrain', 30: 'sky', 31: 'void-ground', 32: 'void-dynamic', 33: 'void-static', 34: 'void-unclear'}
Let's assign colors to each category 🎨. This will help us visualize the segmentation results more effectively and make it easier to interpret the different categories in our images.
We can visualize some examples from the dataset, including the RGB image, the corresponding mask, and an overlay of the mask on the image. This will help us better understand the dataset and how the masks correspond to the images. 📸






4. Visualize Class Occurrences 📊
To gain deeper insights into the dataset, let’s plot the occurrences of each class. This will allow us to understand the distribution of classes and identify any potential biases or imbalances in the dataset.

5. Initialize Image Processor and Add Data Augmentation with Albumentations 📸
We will start by initializing the image processor and then apply data augmentation 🪄 using Albumentations. This will help enhance our dataset and improve the performance of our semantic segmentation model.
6. Initialize Model from Checkpoint
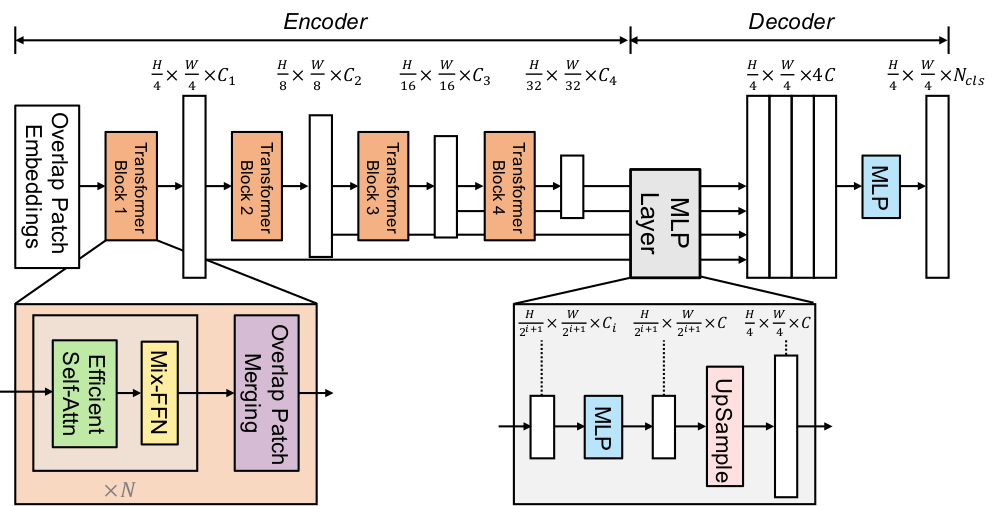
We will use a pretrained Segformer model from the checkpoint: nvidia/mit-b0. This architecture is detailed in the paper SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers and has been trained on ImageNet-1k.
7. Set Training Arguments and Connect to Weights & Biases 📉
Next, we'll configure the training arguments and connect to Weights & Biases (W&B). W&B will assist us in tracking experiments, visualizing metrics, and managing the model training workflow, providing valuable insights throughout the process.
8. Set Custom compute_metrics Method for Enhanced Logging with evaluate
We will use the mean Intersection over Union (mean IoU) as the primary metric to evaluate the model’s performance. This will allow us to track performance across each category in detail.
Additionally, we’ll adjust the logging level of the evaluation module to minimize warnings in the output. If a category is not detected in an image, you might see warnings like the following:
RuntimeWarning: invalid value encountered in divide iou = total_area_intersect / total_area_union
You can skip this cell if you prefer to see these warnings and proceed to the next step.
9. Train the Model on Our Dataset 🏋
Now it's time to train the model on our custom dataset. We’ll use the prepared training arguments and the connected Weights & Biases integration to monitor the training process and make adjustments as needed. Let’s start the training and watch the model improve its performance!
TrainOutput(global_step=2000, training_loss=0.8801042995750904, metrics={'train_runtime': 5698.7353, 'train_samples_per_second': 2.808, 'train_steps_per_second': 0.351, 'total_flos': 2.81087582404608e+17, 'train_loss': 0.8801042995750904, 'epoch': 20.0}) 10. Evaluate Model Performance on New Images 📸
After training, we’ll assess the model’s performance on new images. We’ll use a test image and leverage a pipeline to evaluate how well the model performs on unseen data.

The model has generated some masks, so we can visualize them to evaluate and understand its performance. This will help us see how well the model is segmenting the images and identify any areas for improvement.

11. Evaluate Performance on the Test Set 📊
{'eval_loss': 0.6063494086265564, 'eval_mean_iou': 0.26682655949637757, 'eval_mean_accuracy': 0.3233445959272099, 'eval_overall_accuracy': 0.834762670692357, 'eval_accuracy_unlabeled': nan, 'eval_accuracy_flat-road': 0.8794976463015708, 'eval_accuracy_flat-sidewalk': 0.9287807675111692, 'eval_accuracy_flat-crosswalk': 0.5247038032656313, 'eval_accuracy_flat-cyclinglane': 0.795399495199148, 'eval_accuracy_flat-parkingdriveway': 0.4010852199852775, 'eval_accuracy_flat-railtrack': nan, 'eval_accuracy_flat-curb': 0.4902816930389514, 'eval_accuracy_human-person': 0.5913439011934908, 'eval_accuracy_human-rider': 0.0, 'eval_accuracy_vehicle-car': 0.9253204043875328, 'eval_accuracy_vehicle-truck': 0.0, 'eval_accuracy_vehicle-bus': 0.0, 'eval_accuracy_vehicle-tramtrain': 0.0, 'eval_accuracy_vehicle-motorcycle': 0.0, 'eval_accuracy_vehicle-bicycle': 0.0013499147866290941, 'eval_accuracy_vehicle-caravan': 0.0, 'eval_accuracy_vehicle-cartrailer': 0.0, 'eval_accuracy_construction-building': 0.8815560533904696, 'eval_accuracy_construction-door': 0.0, 'eval_accuracy_construction-wall': 0.4455930603622635, 'eval_accuracy_construction-fenceguardrail': 0.3431640802292688, 'eval_accuracy_construction-bridge': 0.0, 'eval_accuracy_construction-tunnel': nan, 'eval_accuracy_construction-stairs': 0.0, 'eval_accuracy_object-pole': 0.24341265579591848, 'eval_accuracy_object-trafficsign': 0.0, 'eval_accuracy_object-trafficlight': 0.0, 'eval_accuracy_nature-vegetation': 0.9478392425169023, 'eval_accuracy_nature-terrain': 0.8560970005175594, 'eval_accuracy_sky': 0.9530036096232858, 'eval_accuracy_void-ground': 0.0, 'eval_accuracy_void-dynamic': 0.0, 'eval_accuracy_void-static': 0.13859852156564748, 'eval_accuracy_void-unclear': 0.0, 'eval_iou_unlabeled': nan, 'eval_iou_flat-road': 0.7270368663334998, 'eval_iou_flat-sidewalk': 0.8484429155310914, 'eval_iou_flat-crosswalk': 0.3716762279636531, 'eval_iou_flat-cyclinglane': 0.6983685965068486, 'eval_iou_flat-parkingdriveway': 0.3073600964845036, 'eval_iou_flat-railtrack': nan, 'eval_iou_flat-curb': 0.3781660047058077, 'eval_iou_human-person': 0.38559031115261033, 'eval_iou_human-rider': 0.0, 'eval_iou_vehicle-car': 0.7473290757373612, 'eval_iou_vehicle-truck': 0.0, 'eval_iou_vehicle-bus': 0.0, 'eval_iou_vehicle-tramtrain': 0.0, 'eval_iou_vehicle-motorcycle': 0.0, 'eval_iou_vehicle-bicycle': 0.0013499147866290941, 'eval_iou_vehicle-caravan': 0.0, 'eval_iou_vehicle-cartrailer': 0.0, 'eval_iou_construction-building': 0.6637240016649857, 'eval_iou_construction-door': 0.0, 'eval_iou_construction-wall': 0.3336225132267832, 'eval_iou_construction-fenceguardrail': 0.3131070176565442, 'eval_iou_construction-bridge': 0.0, 'eval_iou_construction-tunnel': nan, 'eval_iou_construction-stairs': 0.0, 'eval_iou_object-pole': 0.17741310577170807, 'eval_iou_object-trafficsign': 0.0, 'eval_iou_object-trafficlight': 0.0, 'eval_iou_nature-vegetation': 0.837720086429597, 'eval_iou_nature-terrain': 0.7272281817316115, 'eval_iou_sky': 0.9005169994943569, 'eval_iou_void-ground': 0.0, 'eval_iou_void-dynamic': 0.0, 'eval_iou_void-static': 0.11979798870649179, 'eval_iou_void-unclear': 0.0, 'eval_runtime': 30.5276, 'eval_samples_per_second': 6.551, 'eval_steps_per_second': 0.819, 'epoch': 20.0}
12. Access the Model Using the Inference API and Visualize Results 🔌
Hugging Face 🤗 provides a Serverless Inference API that allows you to test models directly via API endpoints for free. For detailed guidance on using this API, check out this cookbook.
We will use this API to explore its functionality and see how it can be leveraged for testing our model.
IMPORTANT
Before using the Serverless Inference API, you need to set the model task by creating a model card. When creating the model card for your fine-tuned model, ensure that you specify the task appropriately.

Once the model task is set up, we can download an image and use the InferenceClient to test the model. This client will allow us to send the image to the model through the API and retrieve the results for evaluation.
We will use the image_segmentation method from the InferenceClient. This method takes the model and an image as inputs and returns the predicted masks. This will allow us to test how well the model performs on new images.
With the predicted masks, we can display the results.
It’s also possible to use the Inference API with JavaScript. Here’s an example of how you can consume the API using JavaScript:
import { HfInference } from "@huggingface/inference";
const inference = new HfInference(HF_TOKEN);
await inference.imageSegmentation({
data: await (await fetch("https://picsum.photos/300/300")).blob(),
model: "sergiopaniego/segformer-b0-segments-sidewalk-finetuned",
});
Extra Points
You can also deploy the fine-tuned model using a Hugging Face Space. For example, I have created a custom Space to showcase this: Semantic Segmentation with SegFormer Fine-Tuned on Segments/Sidewalk.

Conclusion
In this guide, we successfully fine-tuned a semantic segmentation model on a custom dataset and utilized the Serverless Inference API to test it. This demonstrates how easily you can integrate the model into various applications and leverage Hugging Face tools for deployment.
I hope this guide provides you with the tools and knowledge to confidently fine-tune and deploy your own models! 🚀